🦖Meet T-REX: The Agent That Thinks Before It Moderates
--and T-REX means Tiered-Risk Exposure eXpert
Why We Built It
Traditional video moderation pipelines are effective but fragmented. They react to violations but don’t plan ahead. We needed an agent that could strategically decide when to recall a video based on its risk level and view growth potential.
The Agent's Job
- Recall high-risk videos as early as possible
- Delay recall of low-risk videos to reduce reviewer burden
- Balance exposure vs. efficiency via trial-and-error learning
Technical Framing
We model moderation timing as a sequential decision problem. T-REX doesn't need to predict exact VV (view volume) growth, only when to act to maximize expected return.
Environment
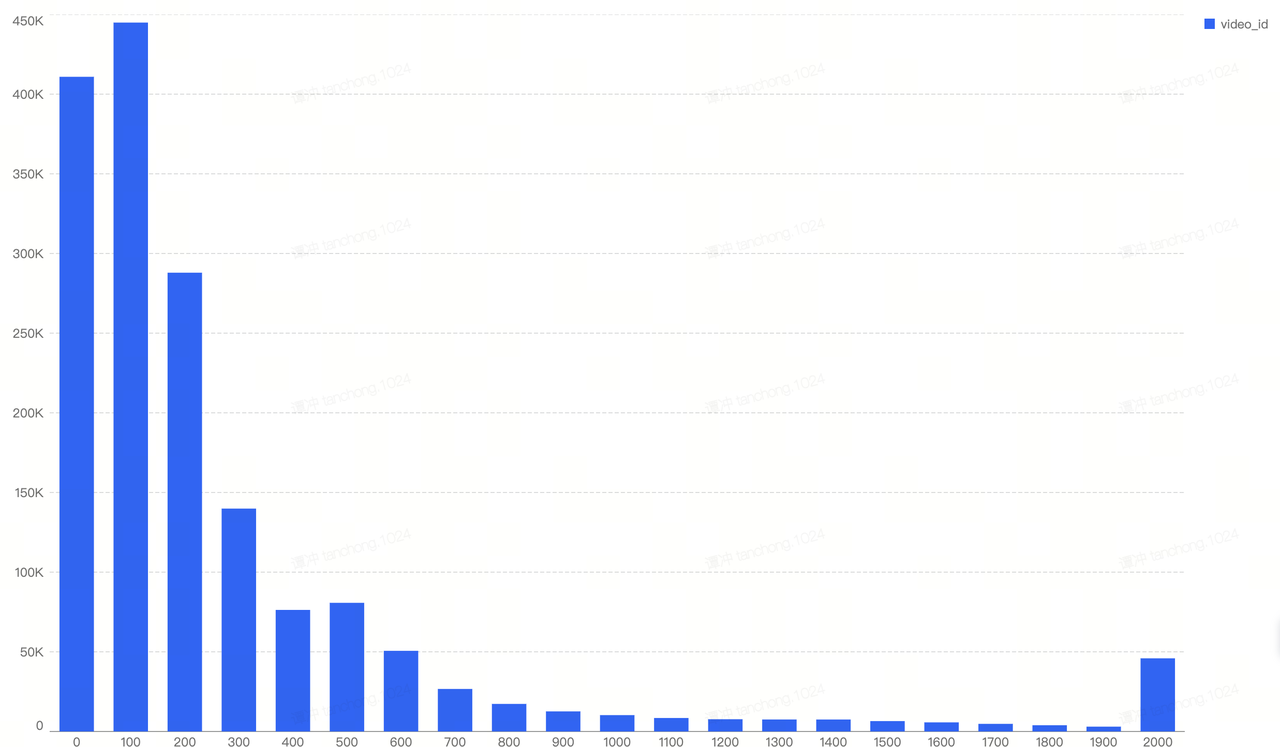
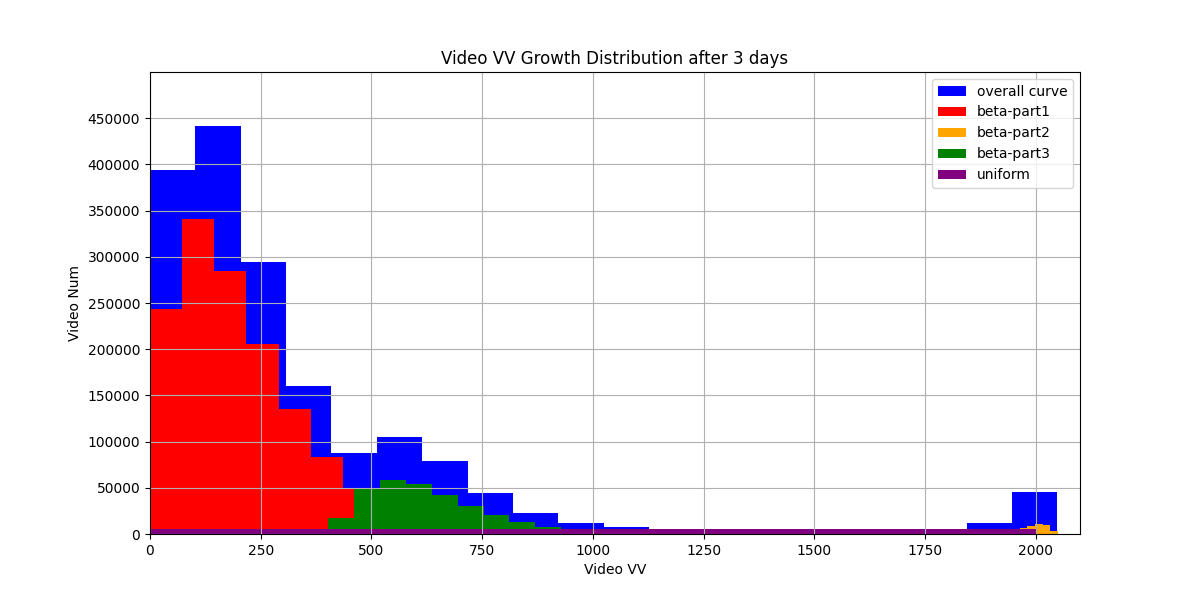
The role of the environment is to provide feedback (rewards) based on the agent’s actions. Specifically, it simulates VV (view volume) sampling and anchoring for each video based on a predefined VV growth trend. Combined with the agent’s predicted recall VV, it calculates the duration of risk exposure and returns a reward accordingly. We simulate the 3-day VV growth trend using three Beta distributions and one Uniform distribution, as shown in the figure below. By overlaying these distributions, we sample and anchor VV values for each video to complete the simulation environment. In future iterations, if actual VV distribution data becomes available, it would be preferable to replace simulated trends with real-world VV data.
Action Space
Given the features of a video, the agent needs to predict an appropriate action—such as recalling the video immediately at 0 VV, or delaying recall until it reaches 200 VV, and so on. We define a discrete action space consisting of 6 options: recall at 0 VV, 200 VV, 400 VV, 600 VV, 800 VV, and 1000 VV.
Reward Function
# Risk Penalty (emperical formula):
R_risk = (3 - risk_level) * recall_days / 8
# Example: For a high-risk video (risk level = 0) recalled at 200 VV, if its VV growth rate is 50 VV/day, it will be recalled in 4 days. Then, R = (3-0)*4/8 = 1.5. For a non-violating video (risk level = 3), the penalty is zero.
# Review Reward (emperical formula):
R_human = 0.5 + (0.3 * recall_days)
# Final Reward:
R_total = 0.1 * R_human - 0.9 * R_risk
Here, λ1 and λ2 are hyperparameters that balance risk control and review efficiency. For simplicity, we set λ1+λ2=1.
Design motivation: The later a video is recalled, the lower the human review cost—but if it's a high-risk case, delayed recall leads to greater risk exposure and higher penalties. The optimal strategy is to recall high-risk content early and delay low-risk content, and the agent must learn to identify risk and strike this balance through continuous interaction with the environment.
Training Procedure
The overall architecture of our model is shown below. It adopts model embeddings and discrete features as the input. We employ AutoDisNN as our encoder due to its great ability of encoding discrete features. We apply meta embedding to reduce model dimension and Mixture of Experts for final prediction heads.
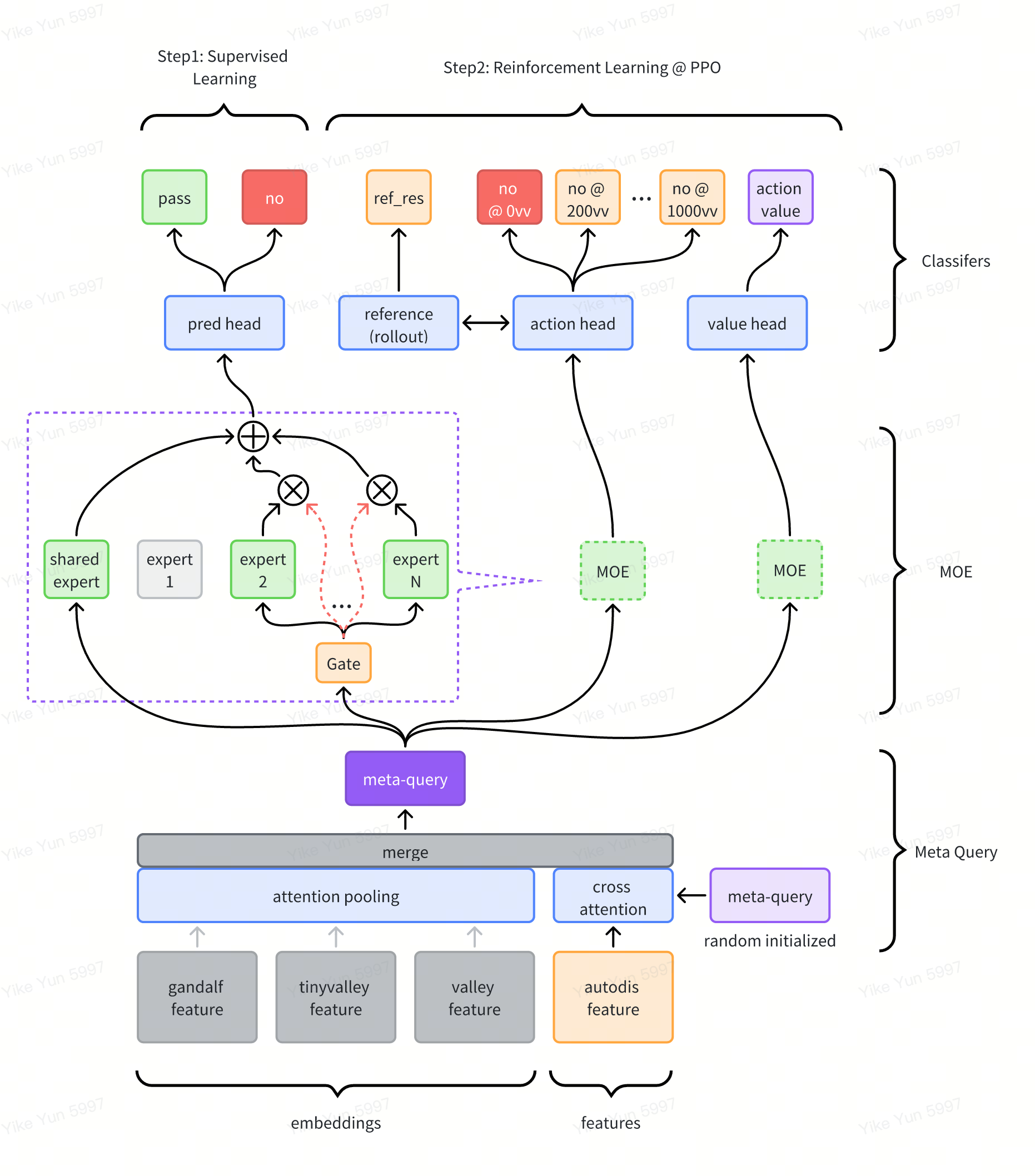
Training steps can be listed as below:
- Supervised training on video labels (risk: yes/no), this is a just a simple binary classification.
- Simulate view growth using beta distributions. This step, we need to simulate the online video VV growth and bind them to each video.
- Train policy via PPO (Proximal Policy Optimization). During this tuning, the model will learn how to sort low and high risks.
Supervised Learning
Supervised learning is quite straight forward, we just need to train our model under a binary classification task.
Simulation
Because our task is to recall high risks ASAP and release low risk tasks, we need to know how much VV a video will gain if it get released online. In this case, we need to simulate each video's VV based on historical data.
We fetched the online VV distribution for videos, and applied 3 Beta Distritbuion to simulate the real distribution. After this step, we can bind the simulated VV to the videos in hand, and assume they will generate this much VV if they get released online.
Reinforcement Learning
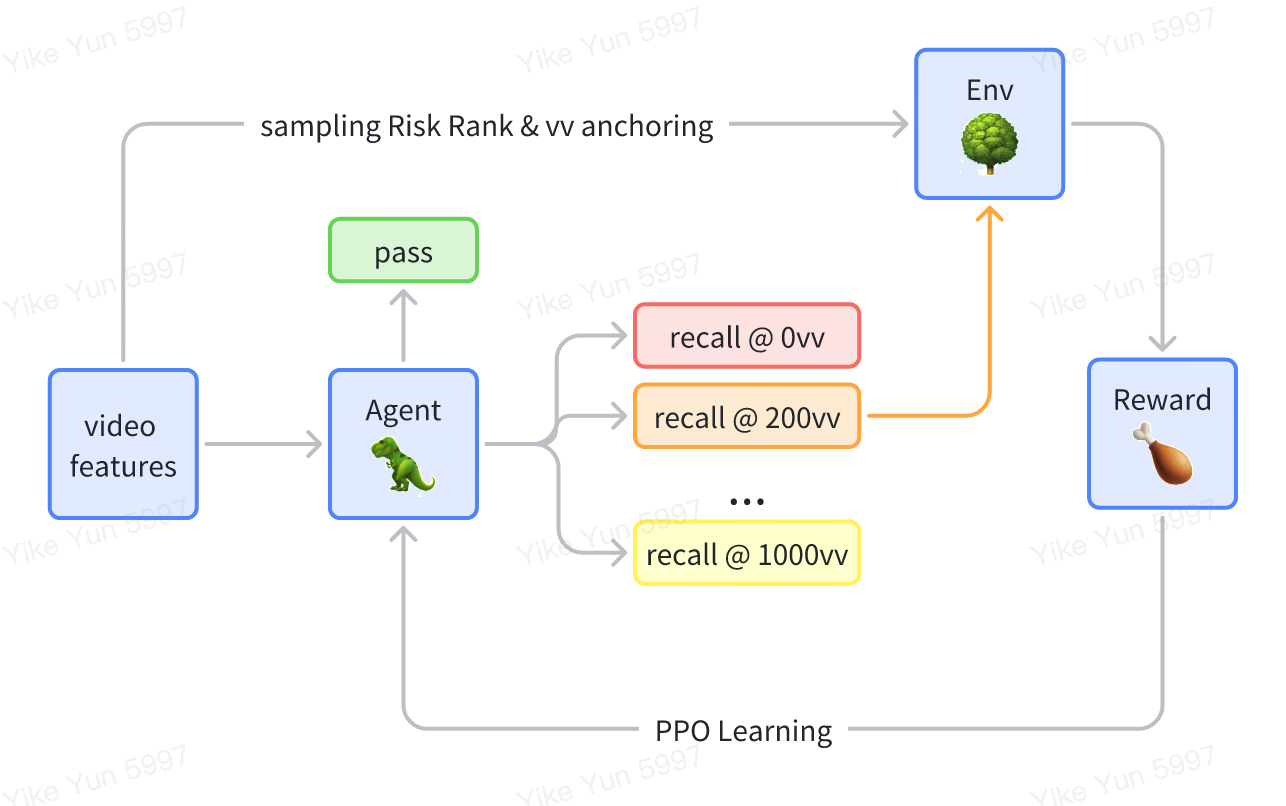
We adopt PPO to train our agent. The overall training architecture is shown below:
Results
Offline:
The following illustrates the policy learned by the model. After reinforcement learning training, the model is able to recall 80% of 0- and 1-point (high-risk) cases on T0, while achieving a 40–30% reduction in T0 review volume. Considering the gradual return of videos over time, the T1+ review reduction effect is around 10–20%.
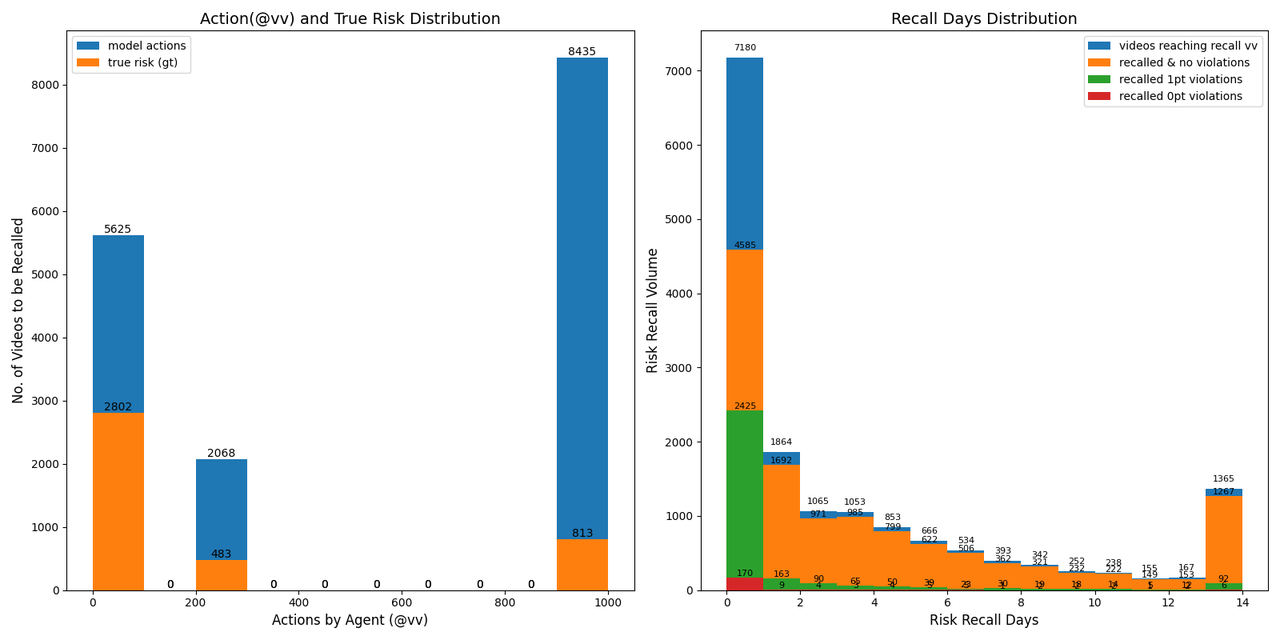
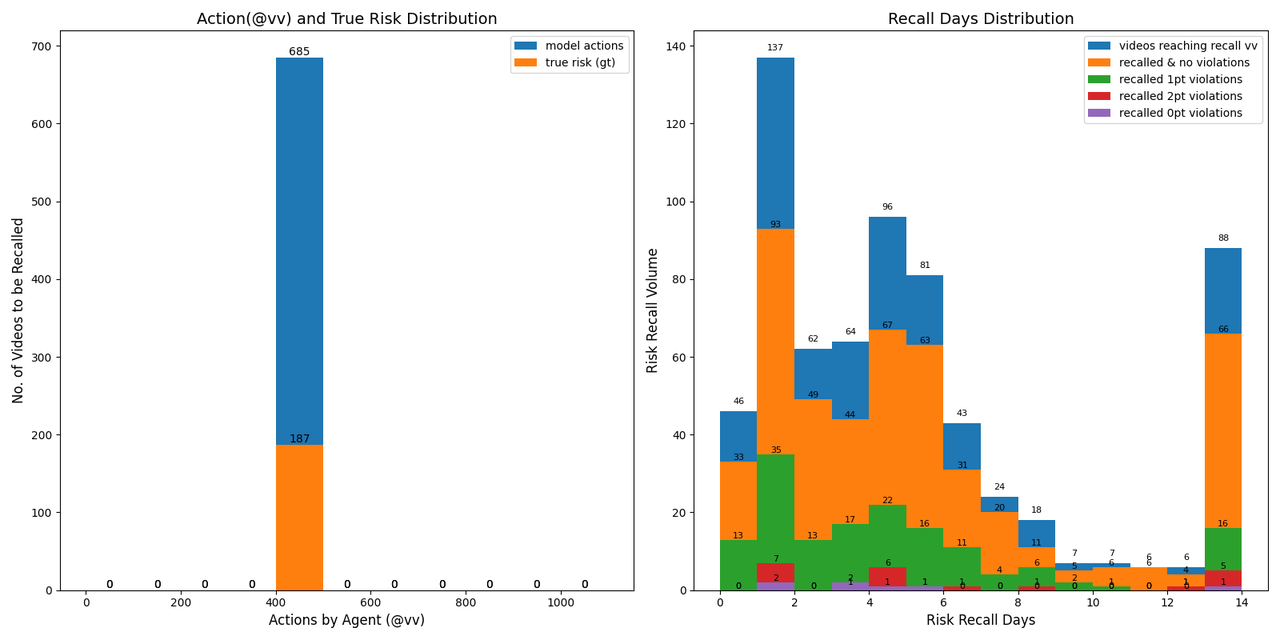
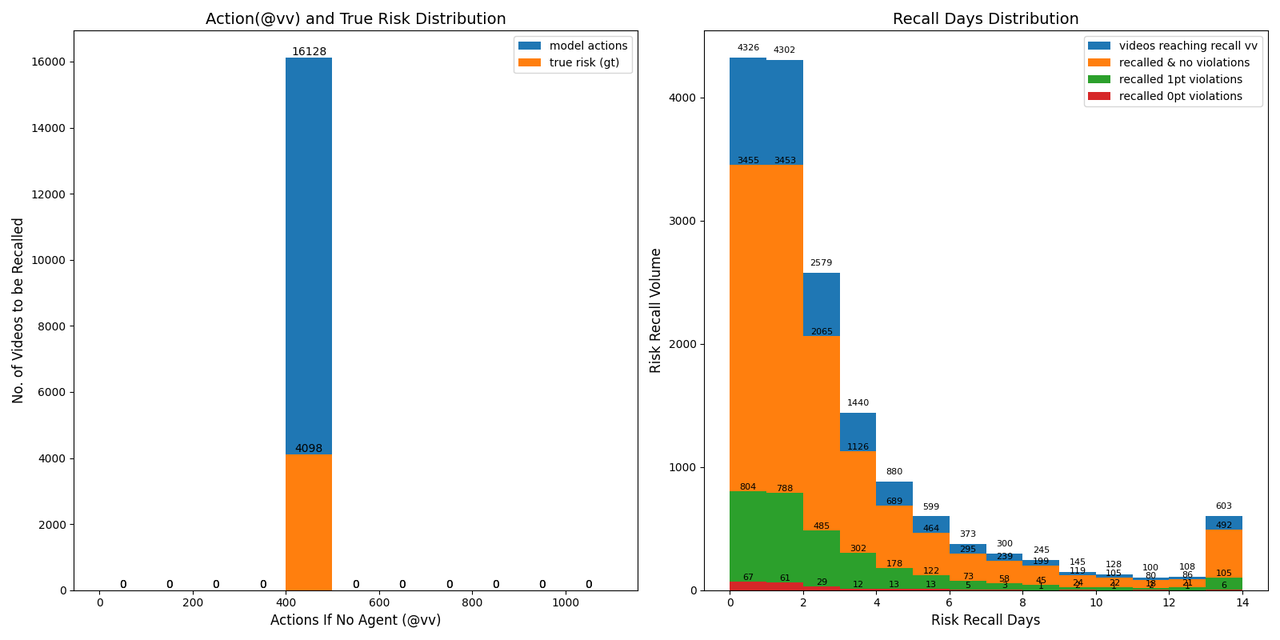
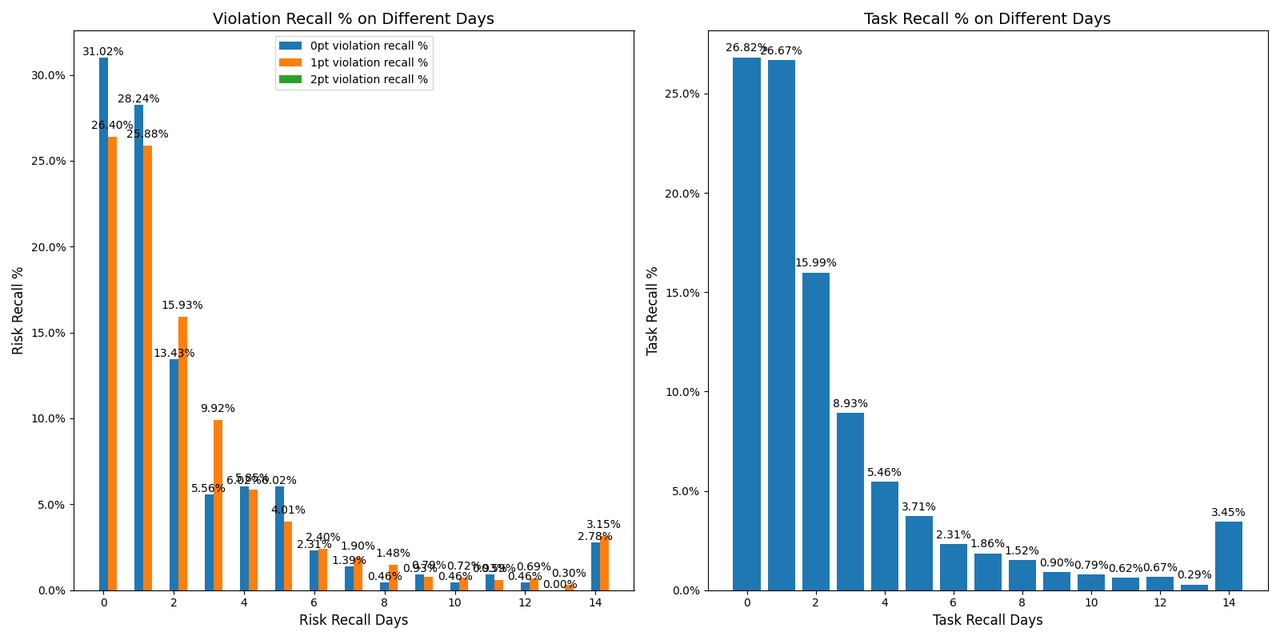
The following shows a comparison of recall behavior when there is no learned policy (recall at 400 VV). As observed, when the model has not learned a policy and relies solely on threshold or specified VV for release, the distribution of risk recall volume is proportional to the daily recall volume (i.e., the risk concentration is uniform), and the daily review volume does not exhibit a clear T0 concentration. In comparison with the policy-learned case above, this further demonstrates that the reinforcement learning–optimized model has learned to balance risk control and review efficiency.
Online A/B Testing:
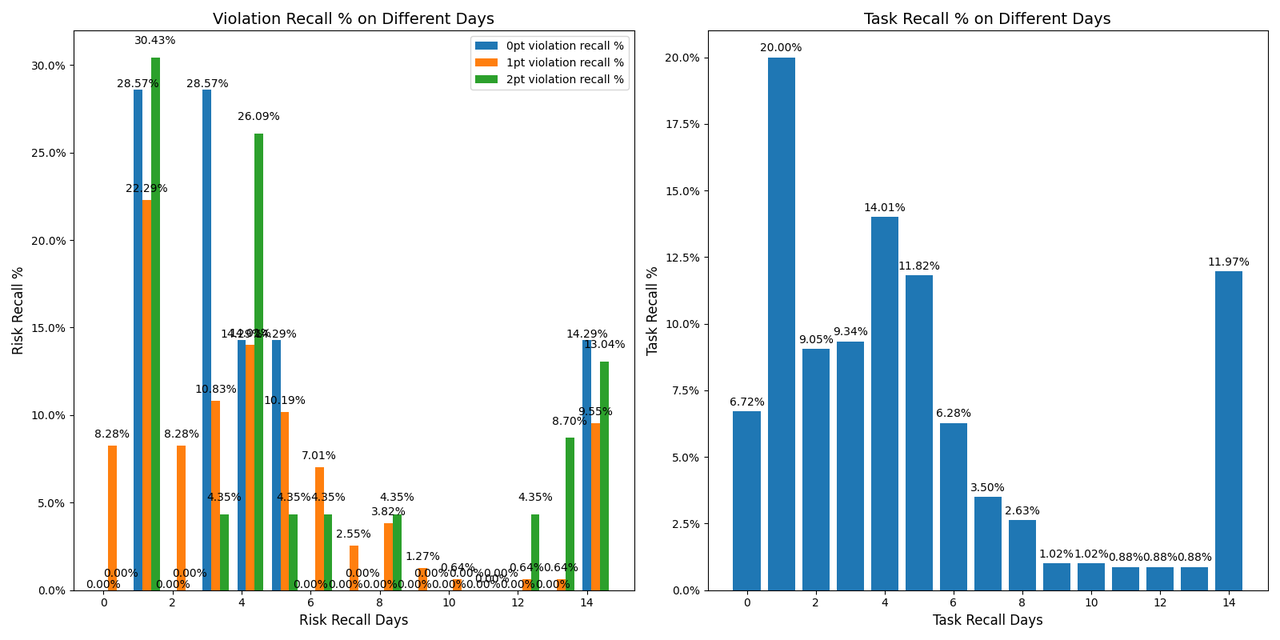
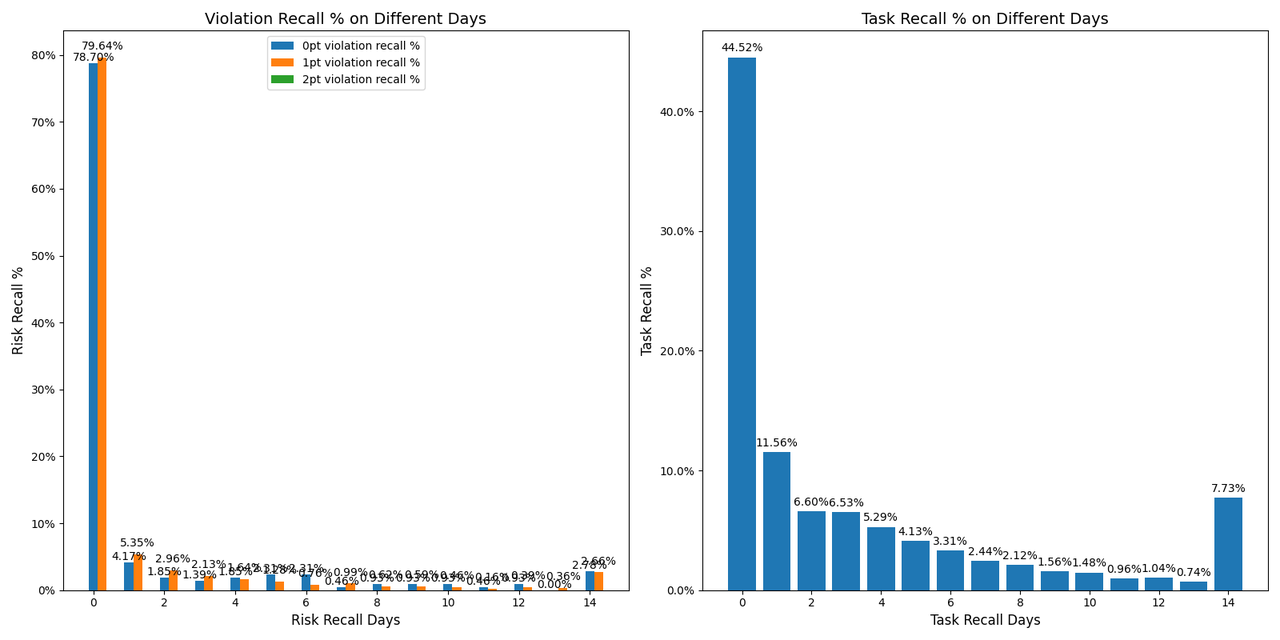
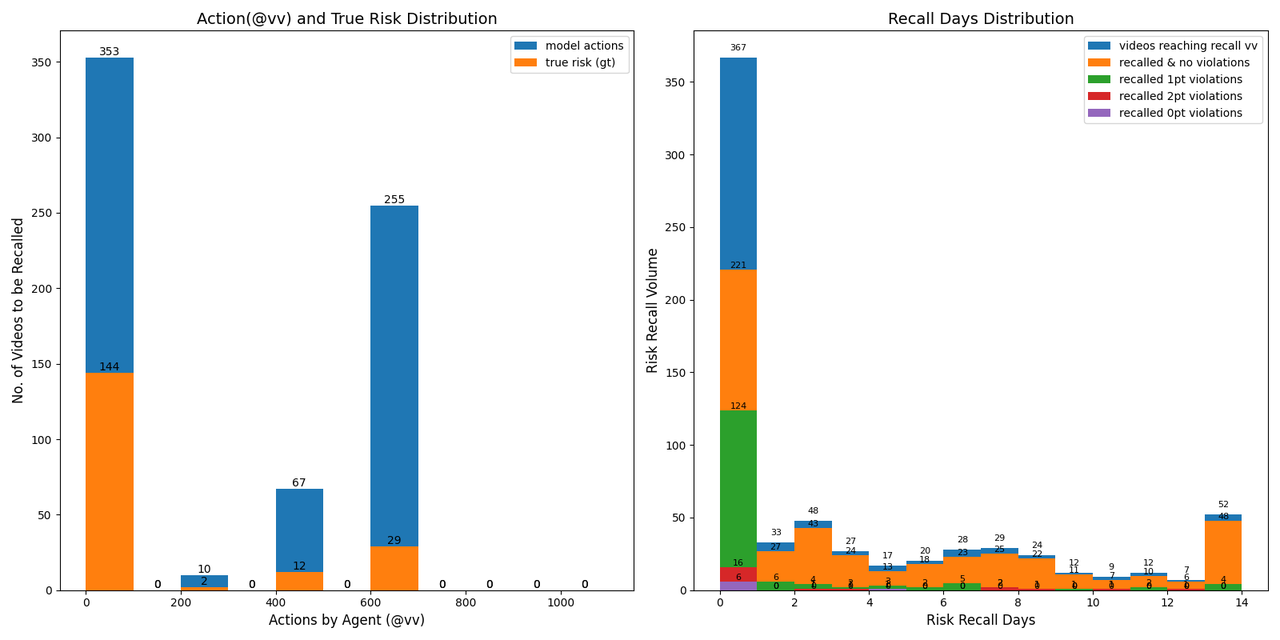
Between May 21 and May 22, a total of 800 model-hit cases were released. On May 25, the videos' cumulative view counts (VV) were collected and the cases were submitted to the review queue to obtain human labels. In the chart below, cases with recall durations of 14 days or more are grouped under “14 days.” With the policy in place, risk concentration exhibited strong T0 clustering: At T0 recall, the proportions of risk scores 0, 1, and 2 were 85%, 80%, and 70% respectively.
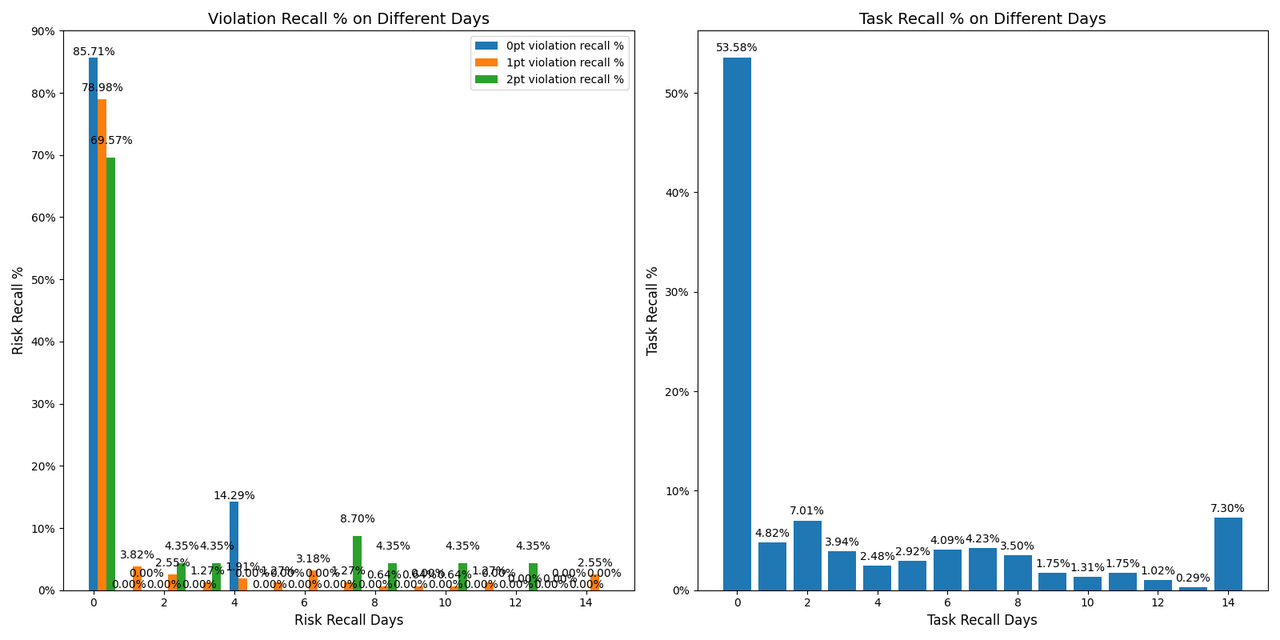
In the chart below, cases with recall durations of 14 days or more are grouped under “14 days.” Under natural inflow, the risk concentration did not exhibit strong clustering, which is consistent with previous estimation experience.